

Can I Use Keras In A Scikit Learn Pipeline
Are you using the "Scikit-learn wrapper" in your Keras Deep Learning model?
How to use the special wrapper classes from Keras for hyperparameter tuning?

Introduction
Keras is one of the most popular go-to Python libraries/APIs for beginners and professionals in deep learning. Although it started equally a stand-alone projection past François Chollet, it has been integrated natively into TensorFlow starting in Version 2.0. Read more about information technology here.
As the official medico says, it is "an API designed for human being beings, not machines" as it "follows best practices for reducing cognitive load".

I of the situations, where the cerebral load is sure to increase, is hyperparameter tuning. Although in that location are then many supporting libraries and frameworks for handling it, for simple filigree searches, we tin e'er rely on some built-in goodies in Keras.
In this article, we will quickly look at ane such internal tool and examine what nosotros can do with it for hyperparameter tuning and search.
Scikit-learn cantankerous-validation and filigree search
Virtually every Python car-learning practitioner is intimately familiar with the Scikit-learn library and its beautiful API with simple methods like fit, get_params, and predict.
The library also offers extremely useful methods for cross-validation, model selection, pipelining, and grid search abilities. If you look around, you lot will find enough of examples of using these API methods for classical ML problems. But how to use the same APIs for a deep learning problem that yous have encountered?
One of the situations, where the cognitive load is sure to increment, is hyperparameter tuning.
When Keras enmeshes with Scikit-learn
Keras offer a couple of special wrapper classes — both for regression and classification problems — to employ the total ability of these APIs that are native to Scikit-larn.
In this article, let me show y'all an case of using simple k-fold cross-validation and exhaustive grid search with a Keras classifier model. It utilizes an implementation of the Scikit-learn classifier API for Keras.
The Jupyter notebook demo can be found here in my Github repo.
Start with a model generating function
For this to work properly, we should create a elementary role to synthesize and compile a Keras model with some tunable arguments built-in. Hither is an instance,

Information
For this demo, we are using the popular Pima Indians Diabetes. This dataset is originally from the National Establish of Diabetes and Digestive and Kidney Diseases. The objective of the dataset is to diagnostically predict whether or not a patient has diabetes, based on certain diagnostic measurements included in the dataset. And so, information technology is a binary classification task.
- We create features and target vectors —
XandY - Nosotros scale the feature vector using a scaling API from Scikit-learn like
MinMaxScaler. Nosotros call thisX_scaled.
That's it for data preprocessing. We can pass this X_scaled and Y directly to the special classes, we will build side by side.
Keras offer a couple of special wrapper classes — both for regression and classification problems — to utilize the full ability of these APIs that are native to Scikit-learn.
The KerasClassifier class
This is the special wrapper grade from Keras than enmeshes the Scikit-acquire classifier API with Keras parametric models. We can pass on various model parameters corresponding to the create_model part, and other hyperparameters like epochs, and batch size to this class.
Here is how nosotros create it,

Notation, how we pass on our model creation office as the build_fn argument. This is an instance of using a role equally a showtime-class object in Python where you tin pass on functions as regular parameters to other classes or functions.
For now, we have stock-still the batch size and the number of epochs we desire to run our model for because we just want to run cross-validation on this model. After, we volition brand these as hyperparameters and practice a grid search to discover the best combination.
x-fold cross-validation
Edifice a 10-fold cross-validation reckoner is like shooting fish in a barrel with Scikit-learn API. Here is the code. Note how we import the estimators from the model_selectionDue south module of Scikit-learn.

Then, nosotros can just run the model with this lawmaking, where we pass on the KerasClassifier object nosotros built before forth with the feature and target vectors. The important parameter hither is the cv where nosotros pass the kfold object nosotros built above. This tells the cross_val_score calculator to run the Keras model with the data provided, in a 10-fold Stratified cross-validation setting.

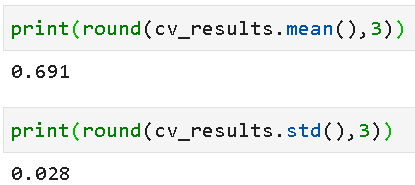
The output cv_results is a unproblematic Numpy array of all the accuracy scores. Why accuracy? Considering that'due south what we chose every bit the metric in our model compiling procedure. We could have chosen any other classification metric like precision, recall, etc. and, in that case, that metric would accept been calculated and stored in the cv_results array.
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy']) We can easily calculate the boilerplate and standard deviation of the x-fold CV run to estimate the stability of the model predictions. This is one of the primary utilities of a cross-validation run.
Lamentatory up the model creation function for grid search
Exhaustive (or randomized) grid search is often a common practice for hyperparameter tuning or to gain insights into the working of a machine learning model. Deep learning models, being endowed with a lot of hyperparameters, are prime candidates for such a systematic search.
In this example, nosotros volition search over the following hyperparameters,
- activation part
- optimizer type
- initialization method
- batch size
- number of epochs
Needless to say that nosotros have to add the kickoff iii of these parameters to our model definition.

So, we create the same KerasClassifier object as earlier,

The search space
We determine to make the exhaustive hyperparameter search infinite size every bit 3×3×3×three×3=243.
Note that the bodily number of Keras runs volition as well depend on the number of cross-validation we choose, as cantankerous-validation will exist used for each of these combinations.
Here are the choices,

That's a lot of dimensions to search over!

Enmeshing Scikit-learn GridSearchCV with Keras
We have to create a lexicon of search parameters and pass it on to the Scikit-learn GridSearchCV estimator. Here is the code,

By default, GridSearchCV runs a 5-fold cantankerous-validation if the cv parameter is not specified explicitly (from Scikit-learn v0.22 onwards). Hither, we go on it at 3 for reducing the total number of runs.
Information technology is advisable to set up the verbosity of GridSearchCVto 2 to keep a visual track of what'due south going on. Remember to go along the verbose=0 for the main KerasClassifier class though, equally you probably don't want to display all the gory details of training private epochs.
And then, only fit!
As we all have come to appreciate the beautifully compatible API of Scikit-learn, information technology is the time to phone call upon that power and but say fit to search through the whole infinite!


Grab a cup of coffee because this may take a while depending on the deep learning model architecture, dataset size, search space complexity, and your hardware configuration.
In total, in that location will exist 729 fittings of the model, 3 cross-validation runs for each of the 243 parametric combinations.
If you don't like full grid search, you lot tin can always effort the random grid search from Scikit-learn stable!
How does the result expect like? Just like you expect from a Scikit-larn estimator, with all the goodies stored for your exploration.

What can y'all do with the result?
You can explore and clarify the results in a number of means based on your research interest or business goal.
What's the combination of the best accurateness?
This is probably on the pinnacle of your listen. Just impress it using the best_score_ and best_params_ attributes from the GridSearchCV figurer.

We did the initial 10-fold cross-validation using ReLU activation and Adam optimizer and got an average accuracy of 0.691. Later doing an exhaustive grid search, we discover that tanh activation and rmsprop optimizer could accept been better choices for this problem. We got amend accurateness!
Extract all the results in a DataFrame
Many a time, we may want to analyze the statistical nature of the performance of a deep learning model under a wide range of hyperparameters. To that finish, it is extremely easy to create a Pandas DataFrame from the grid search results and clarify them further.
Here is the result,

Analyze visually
Nosotros can create beautiful visualizations from this dataset to examine and clarify what selection of hyperparameters improves the performance and reduces the variation.
Hither is a set of violin plots of the mean accuracy created with Seaborn from the grid search dataset.
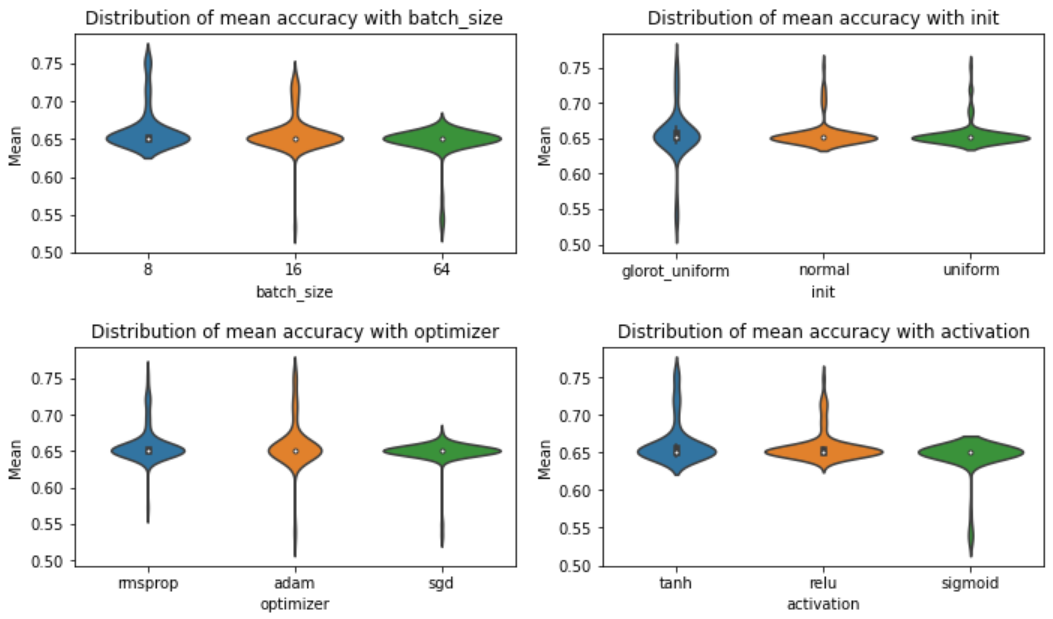
Here is some other plot,

…information technology is extremely like shooting fish in a barrel to create a Pandas DataFrame from the filigree search results and analyze them further.
Summary and further thoughts
In this commodity, we went over how to use the powerful Scikit-learn wrapper API, provided by the Keras library, to do x-fold cross-validation and a hyperparameter grid search for achieving the all-time accuracy for a binary classification problem.
Using this API, it is possible to enmesh the best tools and techniques of Scikit-learn-based general-purpose ML pipeline and Keras models. This approach definitely has a huge potential to save a practitioner a lot of time and effort from writing custom code for cross-validation, filigree search, pipelining with Keras models.
Again, the demo code for this instance can exist constitute here. Other related deep learning tutorials can be found in the same repository. Please experience free to star and fork the repository if y'all like.
You tin bank check the author's GitHub repositories for code, ideas, and resource in machine learning and data science. If you are, like me, passionate about AI/machine learning/information science, delight feel free to add me on LinkedIn or follow me on Twitter.

Source: https://towardsdatascience.com/are-you-using-the-scikit-learn-wrapper-in-your-keras-deep-learning-model-a3005696ff38
Posted by: princethatic.blogspot.com
0 Response to "Can I Use Keras In A Scikit Learn Pipeline"
Post a Comment